
Data Mining
Важность использования технологий хранилищ данных как информационной основы для Data Mining уже рассматривалась нами. Структура хранилища, оптимизированная под задачи аналитической обработки, позволяет свести к минимуму потери времени на поиск нужных данных и получение промежуточных результатов.
Подход SAS к созданию информационно-аналитических систем
Подход компании SAS к созданию информационно-аналитических систем стандартизован в рамках SAS Intelligent Warehousing solutions, рис. 23.2.
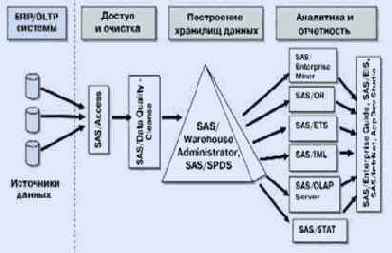
Специализированное хранилище данных 2
Технические требования пакета SASR Enterprise Miner
Архитектура системы
PolyAnalyst Workplace - лаборатория аналитика
Аналитический инструментарий PolyAnalyst
Алгоритмы кластеризации
Алгоритмы классификации
Алгоритмы ассоциации
Модули текстового анализа
Text Analysis (ТА) - текстовый анализ
Визуализация
Эволюционное программирование
Общесистемные характеристики PolyAnalyst
PolyAnalyst Scheduler - режим пакетной обработки
WebAnalyst
WebAnalyst 2
WebAnalyst 3
WebAnalyst 4
WebAnalyst 5
WebAnalyst 6
WebAnalyst 7
Система STATISTICA Data Miner
Система STATISTICA Data Miner 2
Средства анализа STATISTICA Data Miner
Средства анализа STATISTICA 2
Средства анализа STATISTICA 3
Средства анализа STATISTICA 4
Средства анализа STATISTICA 5
Средства анализа STATISTICA 6
Средства анализа STATISTICA 7
Средства анализа STATISTICA 8
Oracle Data Mining
Oracle Data Mining -функциональные возможности
Краткая характеристика алгоритмов классификации
Алгоритмы кластеризации
Поддержка процесса от разведочного анализа до отображения данных
Поддержка процесса от разведочного анализа до отображения данных 2
Архитектура Deductor Studio
Архитектура Deductor Studio 2
Архитектура Deductor Studio 3
Архитектура Deductor Warehouse
Описание аналитических алгоритмов
Описание аналитических алгоритмов 2
Обнаружение дубликатов и противоречий
Обнаружение дубликатов и противоречий 2
Обнаружение дубликатов и противоречий 3
Реинжиниринг аналитического процесса
Технические характеристики продукта
Предпосылки создания KXEN
Предпосылки создания KXEN 2
Структура KXEN Analytic Framework Version 3.0
Структура KXEN Analytic Framework 2
Структура KXEN Analytic Framework 3
Структура KXEN Analytic Framework 4
Технология IOLAP
Data Mining-услуги
Data Mining-услуги 2
Работа с клиентом
Цикл состоит из пяти этапов.
Примеры решения
Техническое описание решения
Техническое описание решения 2
Техническое описание решения 3
Выводы
Искусственный интеллект и экспертные системы
Типичное изучение математики (как и любой формальной теории) в школе, в вузе сопровождается ощущением растерянности, недоумения. Определения и доказательства преподносят как настоящую реальность, но причины явлений никогда не объясняются. Казалось, что большую часть доказательств преподаватели получают с помощью магических манипуляций с кусочком мела у доски. Как можно было связать воедино все эти линии и не выпустить из поля зрения ни одну из них от самого начала доказательства до его чудесного конца? И над всем этим: "А для чего все это надо?".Ответ приходит через несколько лет активной жизни. На самом деле все это ни для чего не надо, потому что предметы, которые вы изучаете, вносятся в школьные и вузовские программы достаточно произвольно. По правде говоря, эти знания служат лишь поводом для перехода к более серьезным вещам, таким как учиться понимать, учиться решать задачи, учиться познавать. Но любопытно, что эти "вещи" не признаются и не преподаются. Можно сказать, что существует определенный вид интеллектуального терроризма, когда некоторых учеников называют "нуль в математике", хотя их единственная вина состоит в том, что они не понимают то, о чем … никогда не говорится. Некоторым удается это избежать, потому что они раньше сумели познакомиться с неявными правилами этой игры. Есть и такие, кто учит все наизусть…
Информационный рынок
Если есть информация должен, просто обязан быть рынок где ее покупают и наоборот продают. И его таки есть. Но информация такой непростой товар который очень хочется спереть у конкурента. Поэтому защите уделяется внимание которое, пожалуй, не встретить на других рынках. И защита крайне специфическая. Ну какой товар такая и защита.Безопасность на инфо. рынке
Защита на на инфо. рынке
Инфо рынокк - Источники
Ключи к на инфо. рынку
Экономика информационного рынка
ИТ - стратегия
Криптография и на инфо. рынок
Надежностьна инфо. рынка
Информационный рынок - Пароли
Стандарты образовательные
IT консалтинг - статьи
Управление ИТ-проектом
Инфо рынок - Протоколы
Информационный рынок - Работа
Информационный рынок - Угрозы
Инфо рынок - Управление
Информационный рынок - Шпионы
Блеск и нищета инфо технологий