
Описаны различные типы грязных данных,
Описаны различные типы грязных данных, среди них выделены следующие группы:
• грязные данные, которые могут быть автоматически обнаружены и очищены;
• данные, появление которых может быть предотвращено;
• данные, которые непригодны для автоматического обнаружения и очистки;
• данные, появление которых невозможно предотвратить.
• пропущенные значения;
• дубликаты данных;
• шумы и выбросы.
Рассмотрим наиболее распространенные виды грязных данных:
Пропущенные значения (Missing Values).
Некоторые значения данных могут быть пропущены в связи с тем, что:
• данные вообще не были собраны (например, при анкетировании скрыт возраст);
• некоторые атрибуты могут быть неприменимы для некоторых объектов (например, атрибут "годовой доход" неприменим к ребенку).
Как мы можем поступить с пропущенными данными?
• Исключить объекты с пропущенными значениями из обработки.
• Рассчитать новые значения для пропущенных данных.
• Игнорировать пропущенные значения в процессе анализа.
• Заменить пропущенные значения на возможные значения.
Дублирование данных (Duplicate Data).
Набор данных может включать продублированные данные, т.е. дубликаты.
Дубликатами называются записи с одинаковыми значениями всех атрибутов.
Наличие дубликатов в наборе данных может являться способом повышения значимости некоторых записей. Такая необходимость иногда возникает для особого выделения определенных записей из набора данных. Однако в большинстве случаев, продублированные данные являются результатом ошибок при подготовке данных.
Как мы можем поступить с продублированными данными?
Существует два варианта обработки дубликатов. При первом варианте удаляется вся группа записей, содержащая дубликаты. Этот вариант используется в том случае, если наличие дубликатов вызывает недоверие к информации, полностью ее обесценивает.
Второй вариант состоит в замене группы дубликатов на одну уникальную запись.
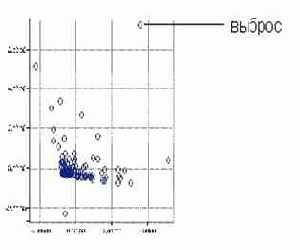
Шумы и выбросы.
Выбросы - резко отличающиеся объекты или наблюдения в наборе данных.
Шумы и выбросы являются достаточно общей проблемой в анализе данных. Выбросы могут как представлять собой отдельные наблюдения, так и быть объединенными в некие группы. Задача аналитика - не только их обнаружить, но и оценить степень их влияния на Достаточно распространена практика проведения двухэтапного анализа - с выбросами и с их отсутствием - и сравнение полученных результатов.
Различные методы Data Mining имеют разную чувствительность к выбросам, этот факт необходимо учитывать при выборе метода анализа данных. Также некоторые инструменты Data Mining имеют встроенные процедуры очистки от шумов и выбросов.
Визуализация данных позволяет представить данные, в том числе и выбросы, в графическом виде. Пример наличия выбросов изображен на диаграмме рассеивания на рис. 18.1. Мы видим несколько наблюдений, резко отличающихся от других (находящихся на большом расстоянии от большинства наблюдений).
Очевидно, что результаты Data Mining на основе грязных данных не могут считаться надежными и полезными. Однако наличие таких данных не обязательно означает необходимость их очистки или же предотвращения появления. Всегда должен быть разумный выбор между наличием грязных данных и стоимостью и/или временем, необходимым для их очистки.